
The final product (so far)
A full-stack content project that scans partner reviews to make a snappy, personalized tagline for over 100k TravelAds properties.
What I did:
Defined the strategy with a “Definition of Good” that set quality, tone, appropriateness, and edge‑case guidelines to steer the model.
Built the working model through prompt engineering and integration work using IntelliJ, RStudio, and Swagger to generate taglines at scale.
Analyzed and validated model outputs against the standards (tone, appropriateness, content), iterated prompts, and surfaced failure modes for remediation.
Why it works
The starting place: while shopping on Expedia, partners would see a carousel of recommended properties. Selections were based largely on location, with sub-factors of similar pricing, star reviews, and amenities.
Where we went: this carousel instantly became more engaging and showed a conductively positive outcome with the addition of a snappy tagline. The cards alone provide information for key amenities, pricing and one photo, and the tagline allows for unique offerings, that guide bookings, shine.

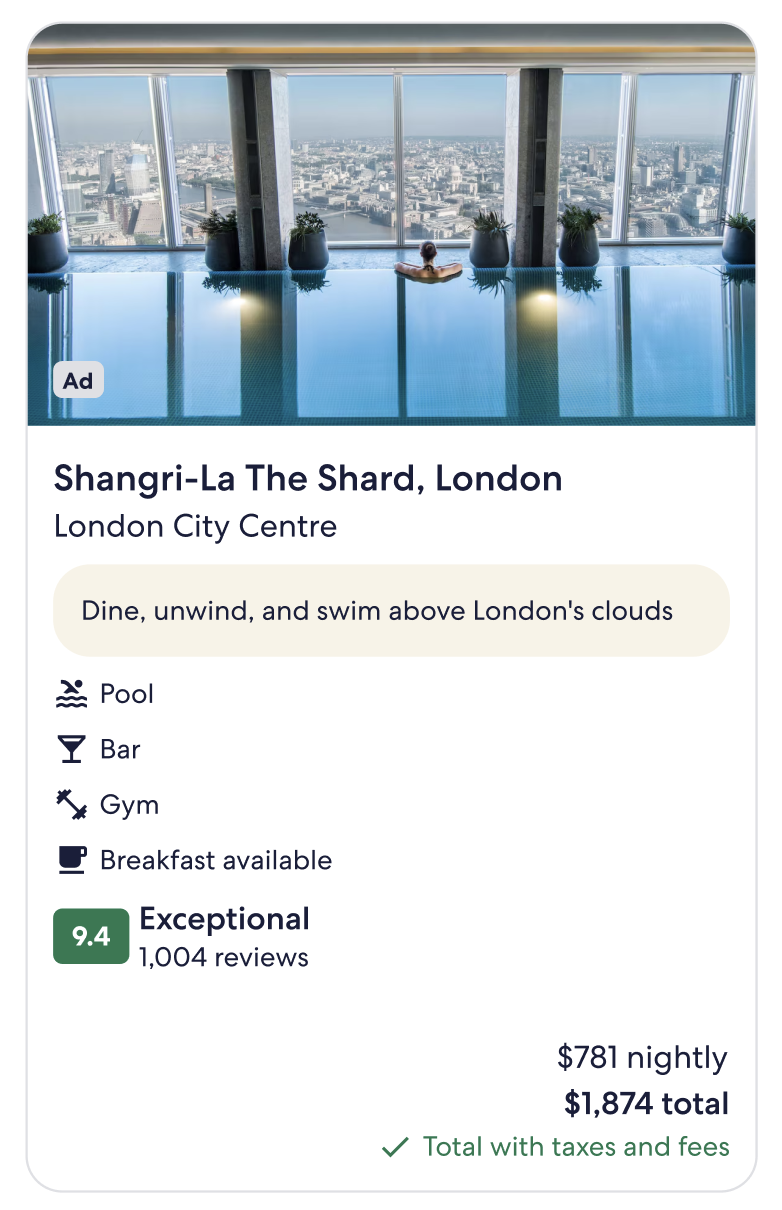
My contributions
-
I authored a comprehensive “Definition of Good” that became the single source of truth for what a successful TravelAd tagline must be. The document codified quality criteria (clarity, factual grounding, brevity), brand and tone guidelines for both Inform and Inspire variants, rules for appropriateness and policy constraints, and an edge‑case catalog describing how to handle contradictions, slang, and ambiguous reviews. That strategy guided every prompt, informed the evaluation rules, and provided clear pass/fail conditions so outputs could be assessed consistently at scale.
-
I implemented the end‑to‑end prompting solution myself, doing prompt engineering and integrations across IntelliJ, RStudio, and Swagger. I developed and iterated prompt templates, control parameters, and example-driven guidance to coax dual‑tone taglines from the model, and used IntelliJ for development, RStudio for exploratory data analysis and batching logic, and Swagger to wire generation into the downstream API surface. I versioned prompts and maintained a reproducible development loop so I could test changes, roll back problematic templates, and scale generation across 100k+ properties.
-
To ensure the outputs met the Definition of Good, I designed and ran an analysis framework that compared generated taglines against standards for tone, appropriateness, and factual content. I combined automated checks with spot human review to surface hallucinations, tone drift, and formatting issues, logged failure modes, and iteratively refined prompts and rules based on those findings. The validation loop made failures visible early, guided targeted fixes, and established a repeatable process for improving quality as the pipeline ran at scale.
In short: everything.
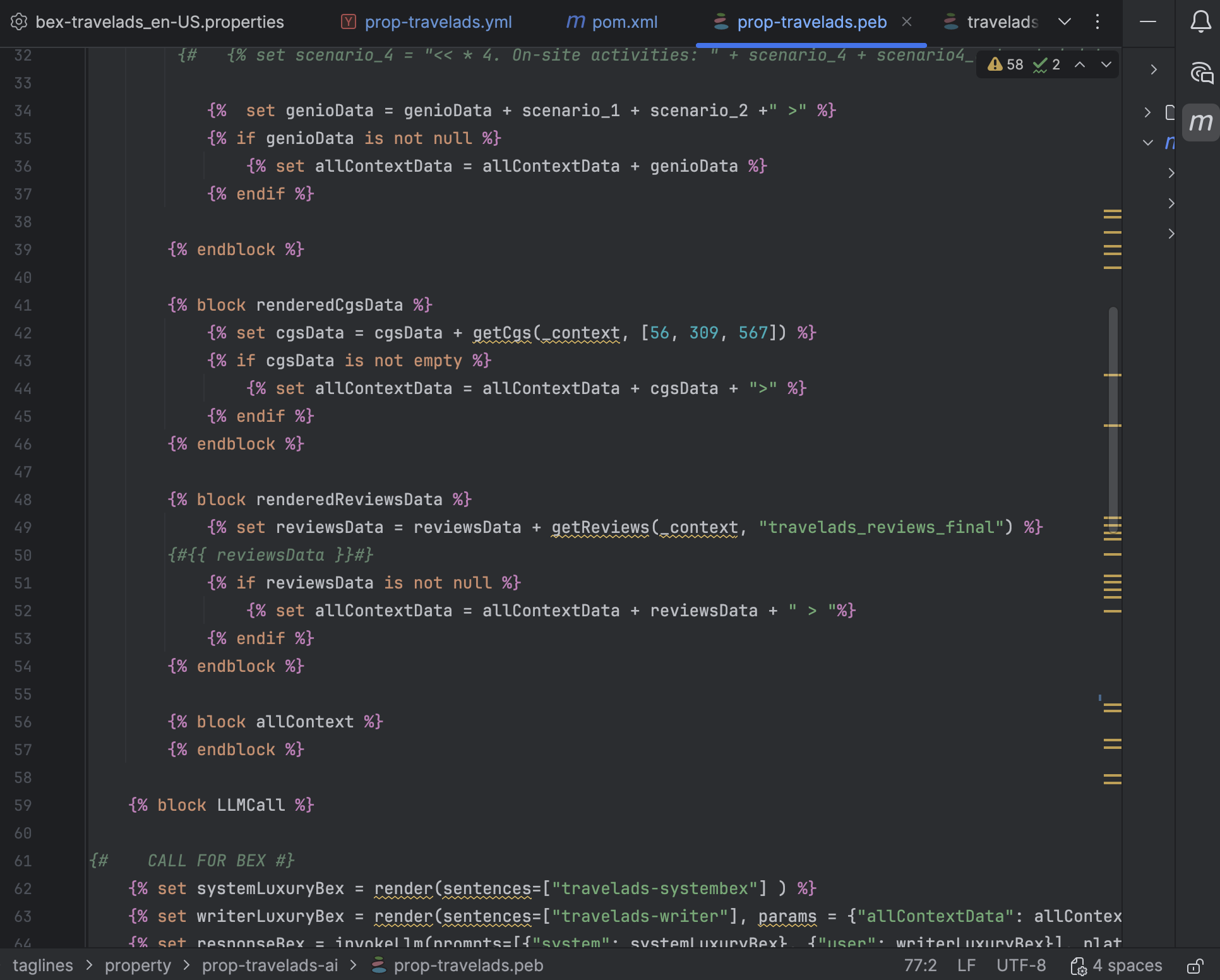
IntelliJ: small-batch prompting
The many tools I used
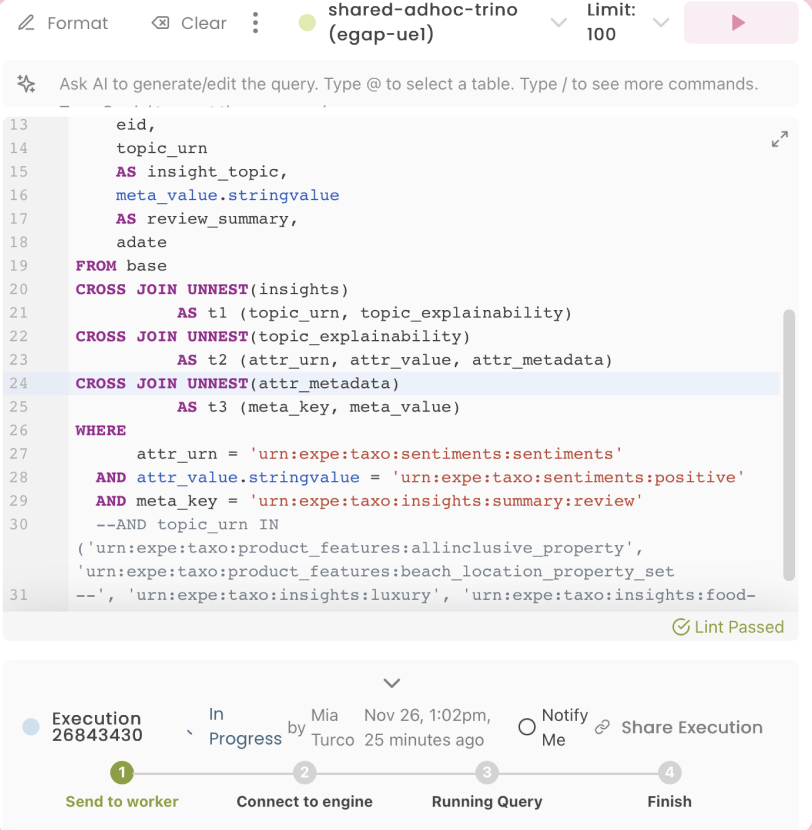
Querybooks: gather review summaries for inputs
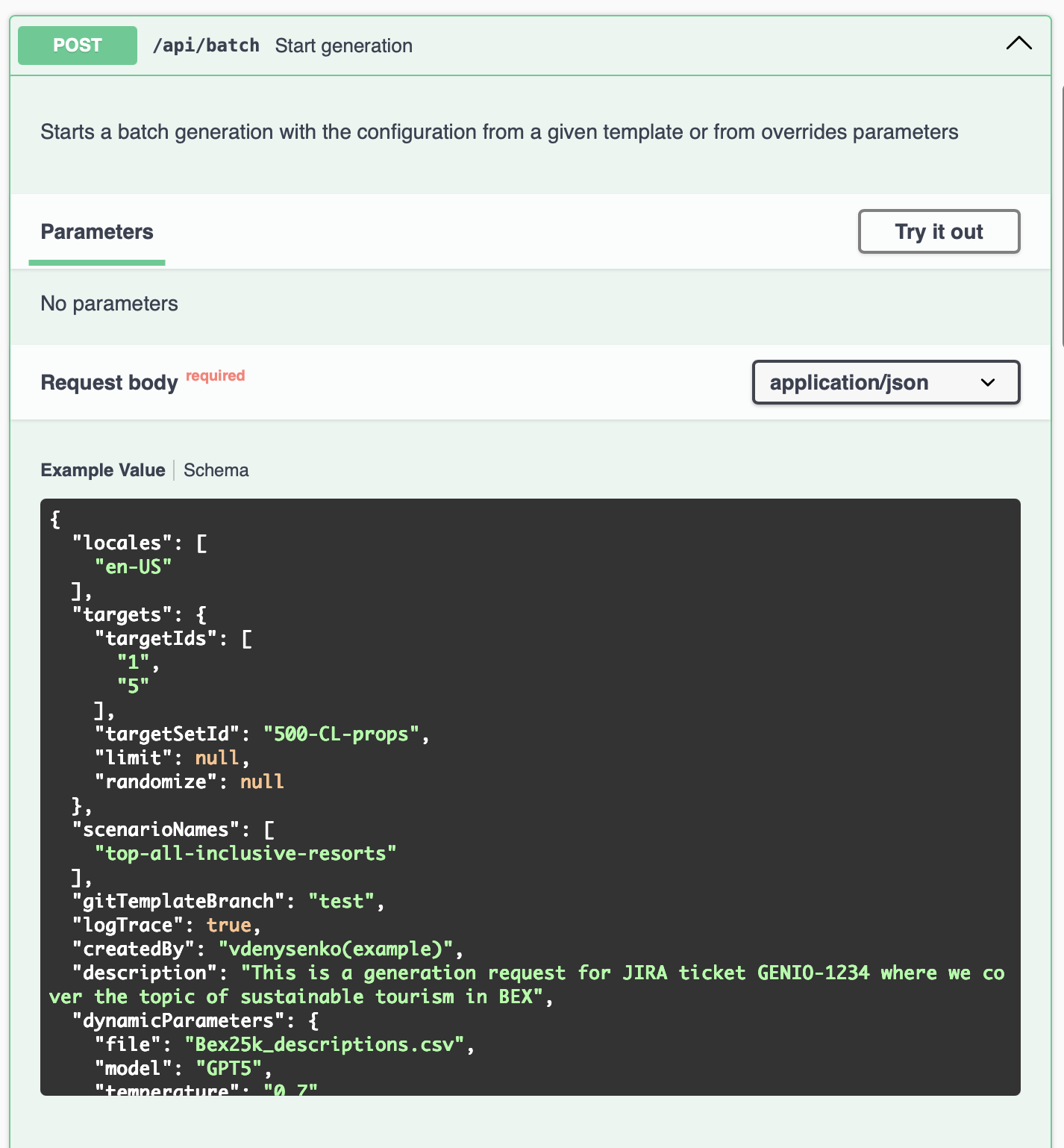
Swagger: prompting at scale for over 100k properties at once

R Studio: for analysis and validation of outputs
Next steps
MVP: The version we are launching in 2026 will be the static, generated taglines using the model I created. Though this has only rolled out to small groups so far, the results have been “conclusively positive”.
Northstar: My vision for this work would be to crank the dial on personalization. Instead of every traveler seeing the same tagline, I’d love it to be based on their preferences and traveler profile, to ensure that the content we’re showing is meaningful and relevant to the user.